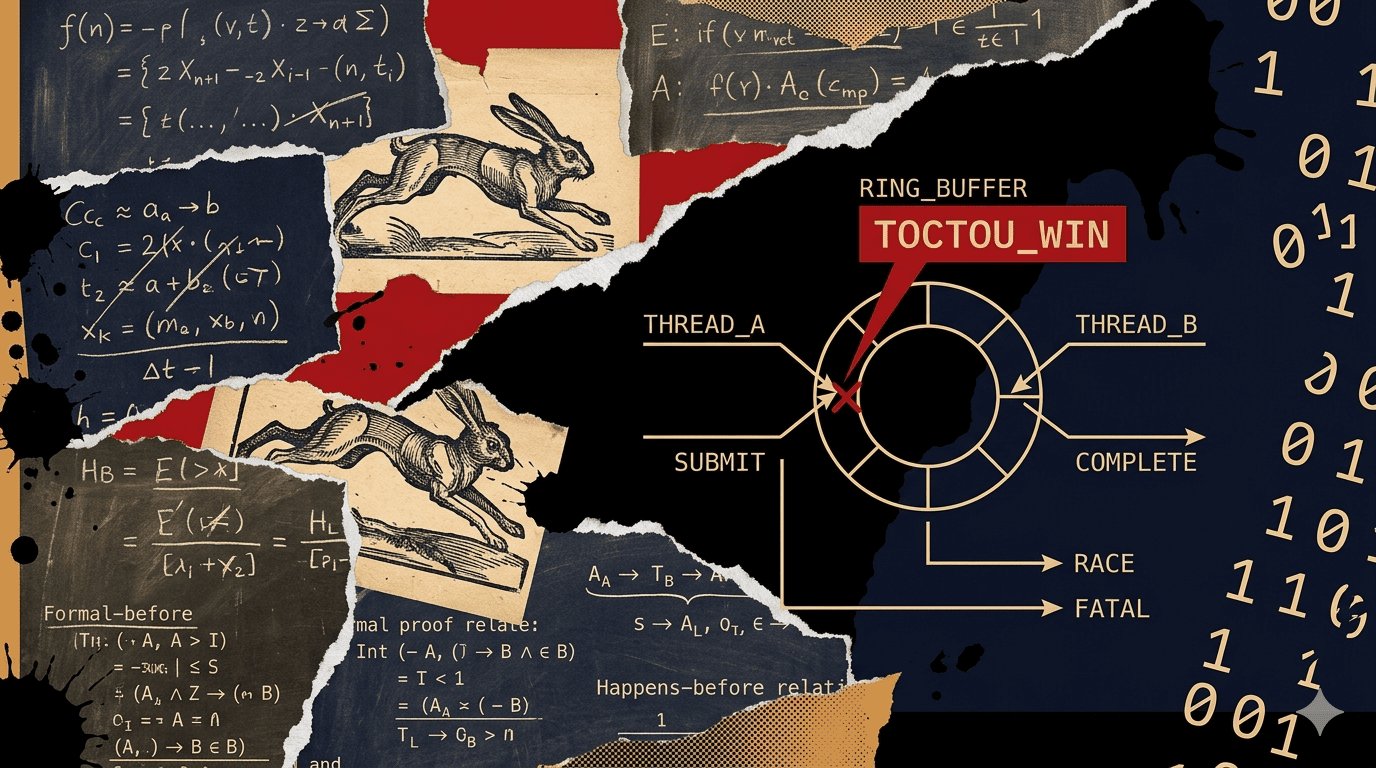
Analysis
CVE-2026-2091 is a time-of-check / time-of-use race in the Linux kernel's io_uring fixed-file-table registration path. An unprivileged local user can race io_uring_register(IORING_REGISTER_FILES_UPDATE) against ring-teardown to trigger a use-after-free on struct cred, then reuse the freed slot to gain effective UID 0. A working PoC has been public on Full Disclosure since April 19 and is weaponized in several container-escape toolkits.
Why io_uring is the worst place for this
io_uring is the fastest I/O surface in modern Linux and, therefore, enabled by default in every mainstream distro since 5.1. Container runtimes mount it inside containers unless explicitly seccomp-filtered. The fixed-file-table model — the exact surface this CVE hits — is a performance optimization that lets long-lived rings pre-register file descriptors, which means many workloads keep rings open across privilege boundaries.
Combine pre-registered tables with the race, and you get an exploit primitive that:
- Does not require
CAP_SYS_ADMINor any capability at all. - Runs from inside a default Docker or containerd container.
- Escapes to host root if the container runs with the host kernel (i.e. everywhere except gVisor / Kata).
- Leaves minimal forensic trace — the race success rate is ~30%, so logs show "weird syscall sequence" not "obvious exploit."
This is the fourth io_uring LPE since 2022. The subsystem is not going away, and the sharp edges are not going away with it. Treat io_uring as a dangerous kernel surface and seccomp-filter it wherever the workload doesn't need it.
Who is exposed
- Any Linux host running kernel 6.1 LTS through 6.7. The LTS cutoff is important — 5.15 LTS is not affected.
- Container workloads using default seccomp profiles (Docker, Kubernetes with the default
RuntimeDefaultseccomp profile still allowsio_uring_*syscalls). - Multi-tenant CI runners (GitHub Actions self-hosted, GitLab runner, Buildkite agents) — attacker PRs can run the PoC and root the runner host.
- Shared Linux hosts (universities, bastion hosts, shell-access shared-hosting).
Mitigation
Upgrade the kernel. Patched versions:
- Mainline:
6.8.9or later. - 6.7 branch:
6.7.11. - 6.6 LTS:
6.6.28. - 6.1 LTS:
6.1.85.
If you can't reboot immediately, the cheapest mitigation is disabling io_uring entirely via sysctl:
sysctl -w kernel.io_uring_disabled=2(requires kernel 6.6+). Set in/etc/sysctl.d/to persist.- For container hosts, add
io_uring_setupandio_uring_registerto the seccomp deny list. - The artifact folder includes a Falco rule that alerts on
IORING_REGISTER_FILES_UPDATEcalls from unprivileged PIDs — decent catch-rate for the public PoC.
The broader pattern
io_uring LPEs are now routine. The kernel team has been patching them quarterly since 2022. If you're not explicitly getting performance from io_uring in a given workload, disable it. The default-on posture made sense for 5.15-era systems that didn't have kernel.io_uring_disabled; it no longer does. Production Linux fleets should treat io_uring the way they treat eBPF — a feature worth having, but locked down to the workloads that actually need it.
The same lesson applies more broadly. Linux kept adding LPE entries through 2026 — CVE-2026-31431 (CopyFail) in April was a different primitive (a four-byte page-cache write through algif_aead), but the same defensive posture catches both: deny-list-by-default for any kernel surface that isn't load-bearing for the workload. AF_ALG, io_uring, eBPF, user namespaces — none of them belong unconditionally enabled in containers running untrusted code.